Super Dataset
Overview
The Super Dataset project is introducing a new alternative way to define, manage and run large corporate models built in AXIS. This new functionality is expected to reduce effort and processing time in preparing large models to be run, and will enable more efficient collaboration of teams working on different components of these large models.
After a prerelease exposure period, the beta release of Super Dataset functionality is now available in the latest versions of EnterpriseLink and AXIS and may be accessed without any additional charges for existing clients for investigation and planning purposes. It is expected that Super Dataset functionality will be available for use in production in the first half of 2023.
How Does the Super Dataset work?
Super Dataset (SD) introduces the option to define and run a large corporate AXIS model that incorporates submodels from multiple smaller AXIS Datasets without the need to consolidate all components into one physical Dataset. Essentially the Super Dataset is a virtual version of a consolidated Dataset.
Initially the Super Dataset will be realized through allowing a Fund object in a given Dataset (called the Lead Dataset) to be extended to incorporate "external" Subfunds found in other Datasets, together with the Subfunds already present in the Lead Dataset.
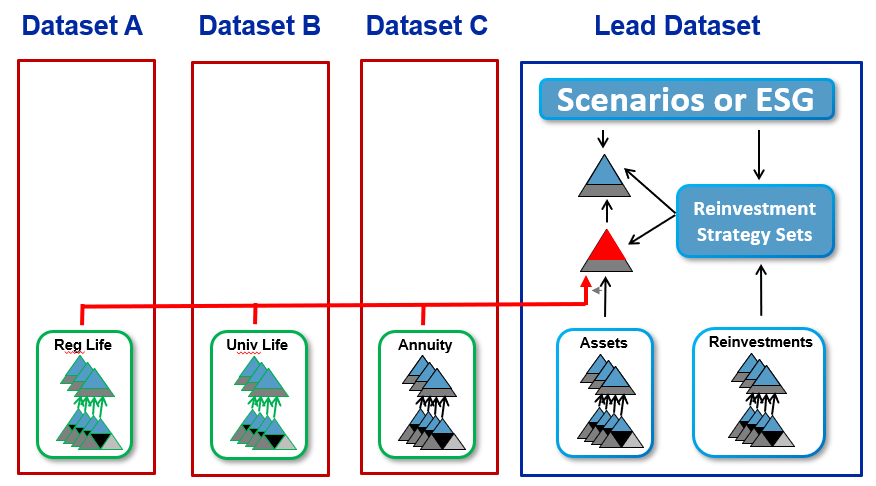
Since the Super Dataset will not physically be consolidated on disk, the required model components are only brought together at the time a batch calculation is launched based on the Extended Fund and its component Subfunds. Initially, Batch Testing Batches including some Embedded Block calculations where applicable, are expected to be supported in the Super Dataset, and other batch types may be added at later dates.
The Super Dataset extends across multiple datasets which may be owned and managed by different teams; as a result, the Super Dataset must be created, managed and used for executing jobs at the EnterpriseLink level.